As previously presented, DBMSs are ubiquitous. DBMS form the critical foundation of Information Systems (individual business systems, research libraries, Worldwide financial management, the WWW and its DNS, etc.). Recall that the WWW has become a dynamic entity (WWW 2.0 built on an n-tier architecture) where content is dynamically maintained on and extracted from a back-end DBMS and processed and formatted for Web presentation. Consider that HTML5 even facilitates/incorporates the implementation of client-side databases to improve personalization, experience, and efficiency. DBMS are also used in networking and system administration to manage users and resources so they are pervasive in all of computing.
Note that when I speak about DBMS I am assuming it is a Relational Database Management System or RDBMS but often we omit the “R” and just write DBMS. As a basis, DBMS is based on relational algebra (see graphic below noting it is data relationship) and set theory. Texts will present other Database models (e.g. flat file, hierarchical, network, object-oriented) but the pervasive model is the RDBMS so I will limit my coverage to RDBMS. You will find a complete DBMS text in this menu system and while much of it is beyond the scope of this course I recommend you return to this resource in your upper-level DBMS and IS Analysis & Design courses.
First, why do we need DBMS?
Today, the success of organizations depends on their ability to:
1. Acquire and maintain accurate timely data about their operations
2. Manage data efficiently and effectively
3. Use data to analyze and guide their activities
=> Note: we just defined IS
Organizations need flexible data management systems to:
1. Get the most from large complex data sets
2. Simplify the tasks of managing this data
3. Extract useful information in a timely fashion
The alternative to DBMS is to use ad hoc approaches – i.e. applications that cannot carry from one domain to another (e.g. vertical applications). As an example, we could store the data and files and write application-specific code to manage it but this is not flexible, scalable, or reusable (i.e. we need a Horizontal application). To illustrate this let’s explore the difference.
File System vs. DBMS
To understand the need for DBMS, let’s consider the following scenarios and apply the CS concepts we have learned this semester.
1. Look at the following flat-file data table where orders are taken and a sequential order number is generated. First, this should make you realize why when you call customer service they typically ask you for your order number first.
| CustomerID | OrderID | LastName | FirstName | Phone | |
|---|---|---|---|---|---|
| 1001 | 3333 | Looby | James | 228-9867 | j@jl.com |
| 3002 | 7334 | Lab | Addie | 376-0012 | a@al.com |
| 4003 | 9335 | Pyrannees | Sam | 987-6543 | s@sp.com |
| 5004 | 2336 | Looby | James | 387-8391 | j@jl.com |
| 6005 | 8337 | Black | Thunder | 499-8876 | b@bt.com |
| 9105 | 8336 | Shepherd | Winter | 499-8877 | w@bt.com |
We can sort the table based on any one column but then every other column is randomly ordered and this is the way it will be saved in storage (i.e. serialized).
From the LM on storage – what type of search do we need to perform if the data is randomly ordered?
From the LM on OS – where does all processing take place? What does the above sorting method mean for a very large data set?
Putting these 2 items together, could Amazon get away with a basic data flat-file approach?
2. Now, let’s understand ACID – Atomicity, Consistency, Isolation & Durability: http://www.ciss100.com/wp-content/uploads/dbms/ACID.pdf
3. Lastly, let’s look at some additional shortcomings of a flat-file approach: http://www.ciss100.com/wp-content/uploads/dbms/Customers.pdf
Here is a video presentation of the above topics.
Let’s put it all together so please consider the following: a company has a large collection (10 Terabyte) of data on employees, departments, products, sales, and so on and 10 TB may be small when we consider product literature and multimedia, customer service information (e.g. think about “this call may be recorded for quality…”, ), images for facial recognition, emergent Big Data, etc..
Employees need to access the data concurrently.
-
-
-
-
-
- Question: what happens to a traditional file if 2 people open it?
- Answer => typically one person gets a read-only copy so full concurrent functionality is not realized.
-
-
-
-
Questions about data must be answered quickly. We can easily store data in a collection of operating system files but we probably do not have 10 TB of main memory to hold data – recall data must be in memory to be accessed and acted upon (i.e. you cannot modify something on disk as it must be brought into memory to be accessed and then written back to disk if modified), therefore we must store data in a storage device and bring relevant parts into main memory for processing as needed. Also, recall a file containing records can only be sorted on a single field so as an example if the records are sorted by the last name, the SSNs, addresses, phone numbers, etc are all in random order. The result, if you wish to search for a particular SSN, you are relegated to transferring data from the hard drive sequentially and then performing a sequential search on all records to find the SSN.
Changes made to the data by different users must be applied consistently (ACID demonstration above). A DBMS must provide for atomic transaction execution in isolation and the data in memory must be written to persistent storage beyond what the OS typically performs.
Access to certain parts of data (e.g. salaries) must be restricted. The OS cannot restrict access on the field level in a file. Consider an Excel file as all fields are available for inspection.
We need a program to identify and address items and we must write special programs to answer each question that users ask about data. We must protect data from inconsistent changes made by concurrent data access and this concurrency must be programmed for each new program. We must also ensure data is restored to a consistent state if the system crashes while changes are being made.
Operating systems provide only password mechanism security and therefore are not sufficiently flexible to enforce security problems where users have access to different subsets of data.
Data redundancy and inconsistency <- duplication of data often results in inconsistencies
Data isolation <- data scattered in various files in different formats
Integrity problems <- consistency constraints difficult to add afterward
Result => The dedicated resulting program is likely to be highly complex and inflexible.
DBMS Description
A DBMS is a collection of interrelated data (Information) and a set of programs to access this data. A DBMS typically describes the activities of one or more related organizations and has 2 components:
1. Data commonly referred to as the database
2. Software designed to assist with maintenance and utilization is Management System. This includes the data dictionary, data description language (DDL), and data manipulation language (DML)
DBMS Abstraction
Abstraction is the difference between the way users think of their data and the way data is ultimately stored => hides the storage and access details.
3 layers of abstraction supported by the DBMS (defined by or known as schemas or views)
1. External schema – Users perception & data access (many conceptual schemas for different users)
2. Conceptual schema – Designed by DBA => normalized data (DB has a single conceptual schema)
3. Physical schema – Physical storage & access (DB has a single physical schema)
A Database has exactly one conceptual schema and 1 physical schema but may have many external schemas each tailored to a particular group of users. Also, it has just one set of stored relations (a relation is a stored table)
External Schema – View Level
Allows data access to be customized (and authorized) at the level of individual users or groups. Forms, reports, and queries for many different users both inside and outside the organization.
External schema design guided by end-user requirements
Example – Reports allow students to view course schedules by times, modality (e.g. on-campus vs. distance learning), by faculty name, or even by campus for large institutions. Forms allow students to register for courses but both reports and forms are based on queries. Faculty on the other hand can see their class lists which include student IDs whereas the students cannot see the full class list and definitely not other student IDs.
Logical or Conceptual Schema
Conceptual Database Design – choice of relations and choice of fields for these relations are not always obvious. The process of arriving at a good conceptual schema requires business analysis and DB normalization. Normalization strives to eliminate redundancy (i.e. repeated data entries) to save space and avoid insertion, deletion, and update anomalies where these anomalies can lose information and/or leave a DB in an inconsistent state.
Example – In a very basic sample university database – relations (tables) contain information about:
Entities such as students, faculty, courses, classes, classrooms, etc.
Relationships such as student enrollments in courses
All student entities described using records and students relation
Each collection of entities and collection of relationships is described as a relation
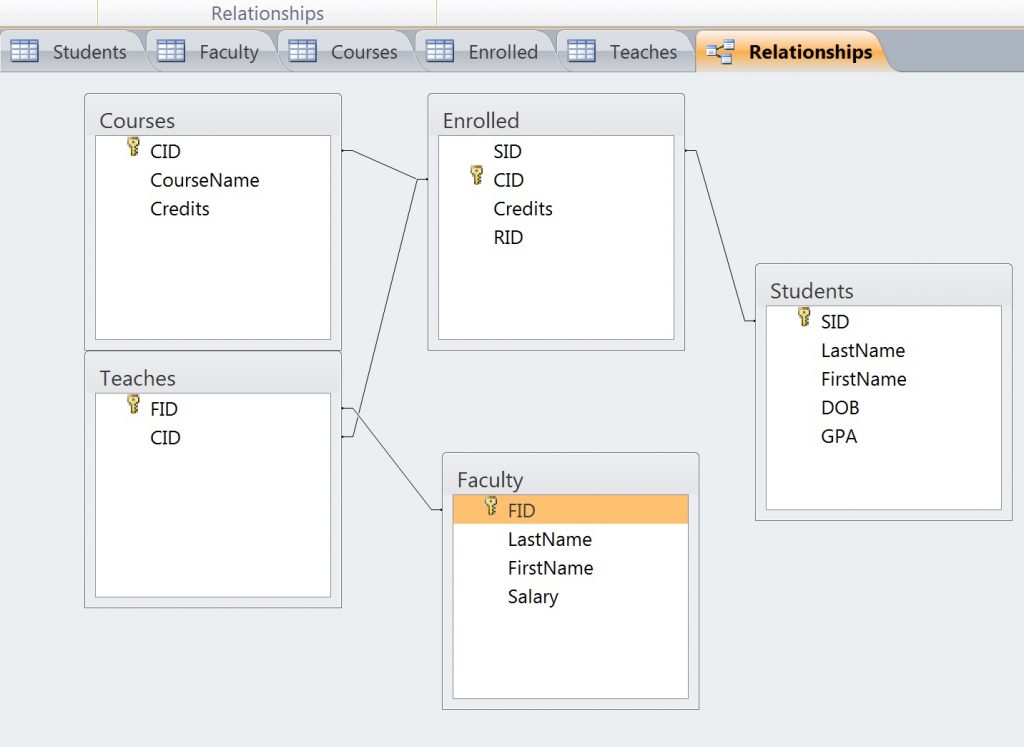
Consider the following conceptual schema for the above business example:
Students(SID: string, LastName: string, FirstName: string, DOB: date, GPA: real)
Faculty(FID:string,LastName: string, FirstName:string, Salary: real)
Courses(CID: string, CourseName: string, Credits: integer)
Enrolled(SID: string, CID: string, Grade: string)
Teaches(FID:string, CID: string)
In the diagram above we can see the primary key/foreign key relationships. Also note the relations or tables exist outside the parenthesis whereas the attributes (domains, fields or columns) have a type or domain associated with them. Note that we can disambiguate identical field names/domain names by fully qualifying the table and domain name (e.g. Faculty.LastName and Student.LastName).
Physical Schema – Specifies storage details – stored on secondary storage devices
File organizations (storage schema)
Auxiliary data structures – e.g. indexes to speed data retrieval operations
Example – In University DB above, it is beneficial to search on courses, students, courses, instructors, etc.
DBMS Structure
A DBMS is partitioned into modules much like an operating system and in fact, it needs OS functionality to access and manage the data effectively. Each module deals with specific responsibilities of overall systems
Unsophisticated users (e.g. customers travel agents)
Sophisticated users (DB administrators programmers)
Web forms
Application front ends
SQL interface
Plan executor – parser operator evaluator optimizer (query eval engine)
Transaction manager files and access methods recovery manager
Lock manager
Buffer manager
Disk space manager
Index files
System catalog
Data files
Advantages of DBMS
Data Independence – Application programs should be independent of details of data representation and storage
Efficient Data Access – DBMS utilizes a variety of sophisticated techniques to store and retrieve data efficiently. This is especially important for data is stored on external storage devices. Recall you can only sort records based on a single field or attribute. If you sort records based on last name, they are unsorted on SSNs and vice versa. To find a particular record based on SSN you would have to search the 1 TB sequentially. Now recall this means bringing every hard drive cluster/sector into memory to read every record sequentially.
Data Integrity & Security – Data always accessed through DBMS can enforce integrity constraints on data. As an example, before inserting salary information for an employee, the DBMS checks that the department budget is not exceeded. Equally important, a DBMS can enforce access controls that govern when/what data is visible to different classes of users (e.g. restrict salary information to HR and directors).
Data Administration – Data redundancy and inconsistency can be improved by centralizing administration. Experienced professionals (this means you) understand the nature of the data being managed that includes:
1. How different groups use it
2. Organize data to minimize redundancy
3. Fine-tune storage and retrieval
Concurrent Access and Crash Recovery – Atomicity or indivisibility. DBMS schedules concurrent accesses the data. Users perceive that data is accessed by one user at a time and protects and recovers from failure.
Reduced Application Development Time – High-level interface to data facilitates quick development of applications. These applications are likely to be more robust than if developed from scratch.
DBMS Disadvantages
Is there ever a reason not to use a DBMS -> a few
1. Applications with tight real-time constraints
2. Applications with just a few well-defined critical operations requiring efficient code
Terminology and Definitions
Entities (or tuples) such as students and faculty courses and classrooms
Relationships between entities such as student’s enrollment in courses, use of rooms etc.
Instance – a snapshot of the database
Example Instance
Sid name login age GPA
5322 Jones HYPERLINK “mailto:Jones@CS” Jones@CS 19 3.4
3344 Smith HYPERLINK “mailto:Smith@cs” Smith@cs 22 2.9
**note date of birth more correct in age since age changes or is computed**
Each row in the students relation is a record or tuple that uniquely describes a student. In this sense, the schema may be regarded as a template for describing a student
Integrity Constraints
We can make the data description more precise by specifying integrity constraints (e.g. conditions that the records in a relation must satisfy)
Example: Every student must have a unique sid. We cannot capture this information by simply adding another field to the students schema and DBMS provides the ability to specify the uniqueness of values in a field. As a result, a DBMS increases the accuracy we may define in our data
Database Languages
Data Definition Language (DDL) – File contains metadata – data about data
Data Manipulation Language (DML) – DBMS allows users to create modify and query data (SQL)
Transaction Management
Example: Consider a database that holds information about airline reservations
At any instant – possible several agents looking up information about available seats and making new reservations. When several users access a database concurrently DBS must order their requests to avoid conflicts. DBMS must protect users from the effects of system failures. Ensure all data is restored to a consistent state when the system restarted after a crash
Transaction
Any single execution of a user program in a DBMS is seen as a basic unit of change. Partial transactions are not allowed and a group of transactions equivalent to serial execution of all transactions
Concurrent execution (OLTP or Multiple Access)
DBMS must schedule concurrent accesses to data allowing each user must be able to ignore the fact others are accessing data
Example (demonstrated in lecture capture above) – Program that deposits cash into account is submitted to DBMS. At the same time another program debits money from the same account. Must serialize the transactions e.g. not interleaved
Locking Protocol – Set of rules to be followed by each transaction enforced by DBMS
Incomplete Transactions and System Crashes
Transactions may be interrupted for running to completion for a variety of reasons. DBMS must ensure changes made by incomplete transactions removed from the database
Example – If DBMS is in the middle of transferring money for account a to account b where account a has been debited but the system crashes before account b is incremented => DB must restore the system to the previous state putting money back into account a (System Log)
System Log records all writes to the database used to bring the database to a consistent state after system crash to reperform/commit or all transactions
To reduce this time, DB periodically forces information to disk – this is called a checkpoint
Textbook Chapter Presentation w/MS Access Application
You will hear me use specific terminology and cite DBMS theory so here is a nice free RDBMS text based on Edgar Codd’s work:
http://www.gitta.info/LogicModelin/en/text/LogicModelin.pdf
DBMS Resources
- ACID.pdf (76.49 Kb)
- Codd Relational Model Text Version 2.pdf (26.91 Mb)
- Codd-Relational-Model-Text.pdf (26.91 Mb)
- Customers.pdf (30.14 Kb)
- DBMS-Isolation-Trace.xlsx (10.84 Kb)
- Data Warehousing - 3 critical capabilities.pdf (785.08 Kb)
In the subsequent pages of this sub-menu structure, you will find the core of DBMS theory and application presented in APA format (to additionally provide you with APA reference papers) distilled from the following references.